概念
AbstractQueuedSynchronizer (抽象队列同步器,简称 AQS),AQS 是很多同步器的基础框架,比如 ReentrantLock、CountDownLatch 和 Semaphore 等都是基于 AQS 实现的。除此之外,我们还可以基于 AQS,定制出我们所需要的同步器。
原理
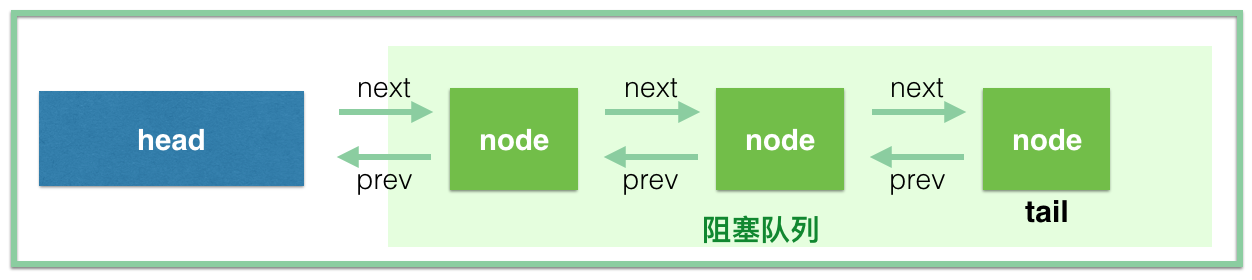
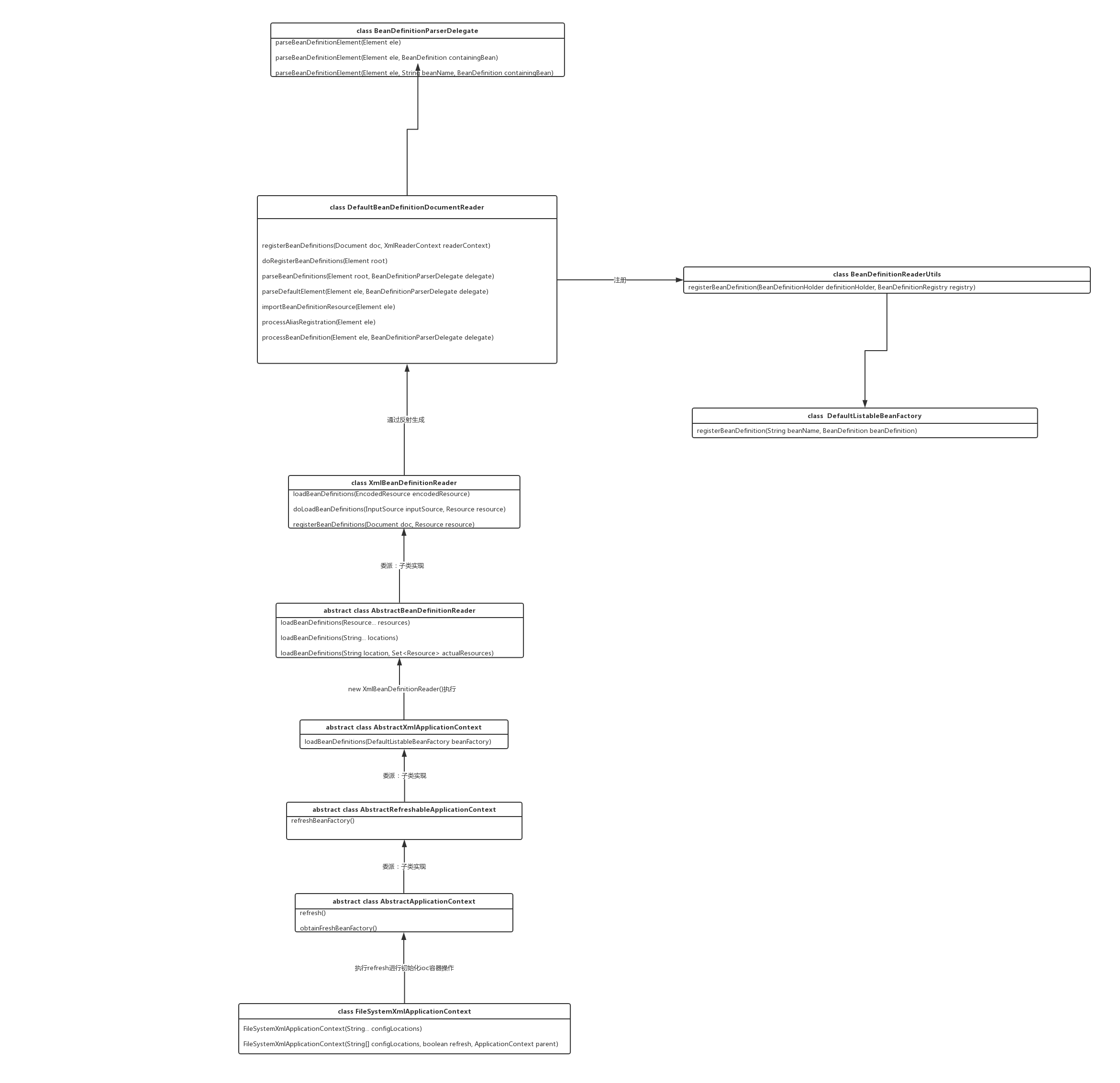
在 AQS 内部,通过维护一个FIFO 队列来管理多线程的排队工作。在公平竞争的情况下,无法获取同步状态的线程将会被封装成一个节点,置于队列尾部。入队的线程将会通过自旋的方式获取同步状态,若在有限次的尝试后,仍未获取成功,线程则会被阻塞住。大致示意图如下: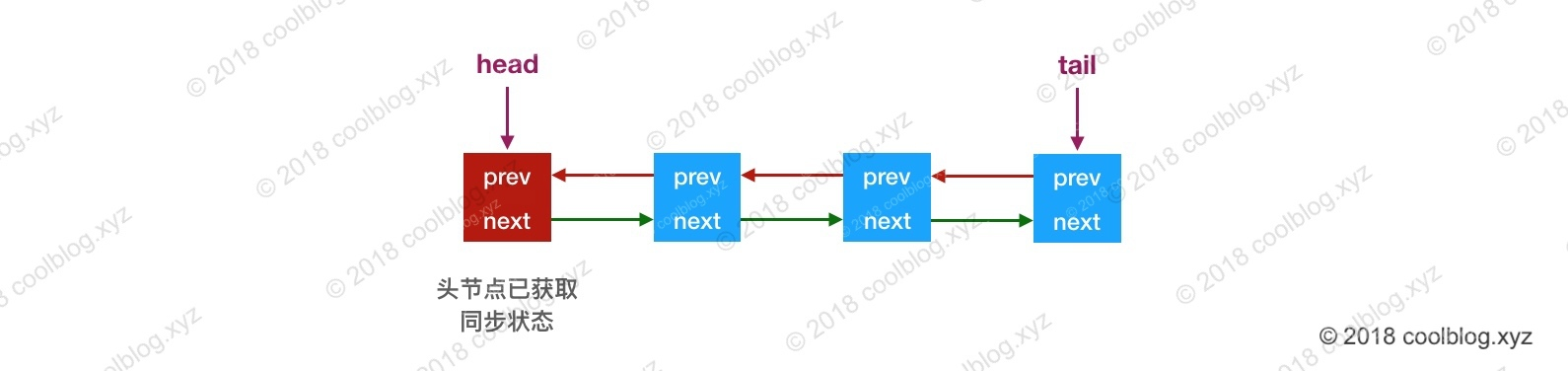
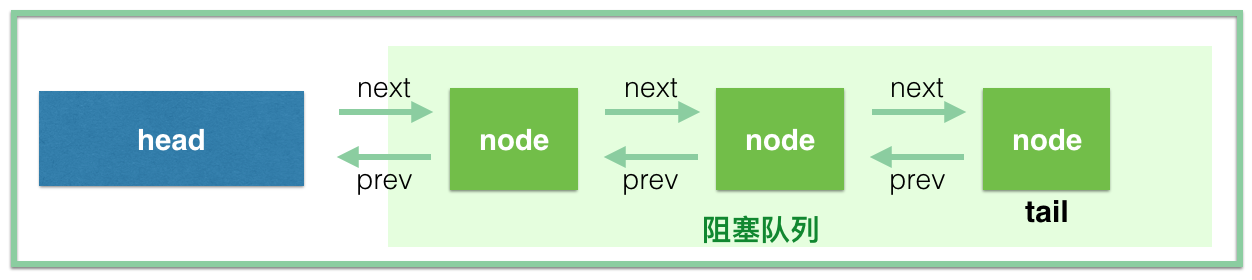
当头结点释放同步状态后,且后继节点对应的线程被阻塞,此时头结点线程将会去唤醒后继节点线程。后继节点线程恢复运行并获取同步状态后,会将旧的头结点从队列中移除,并将自己设为头结点。大致示意图如下: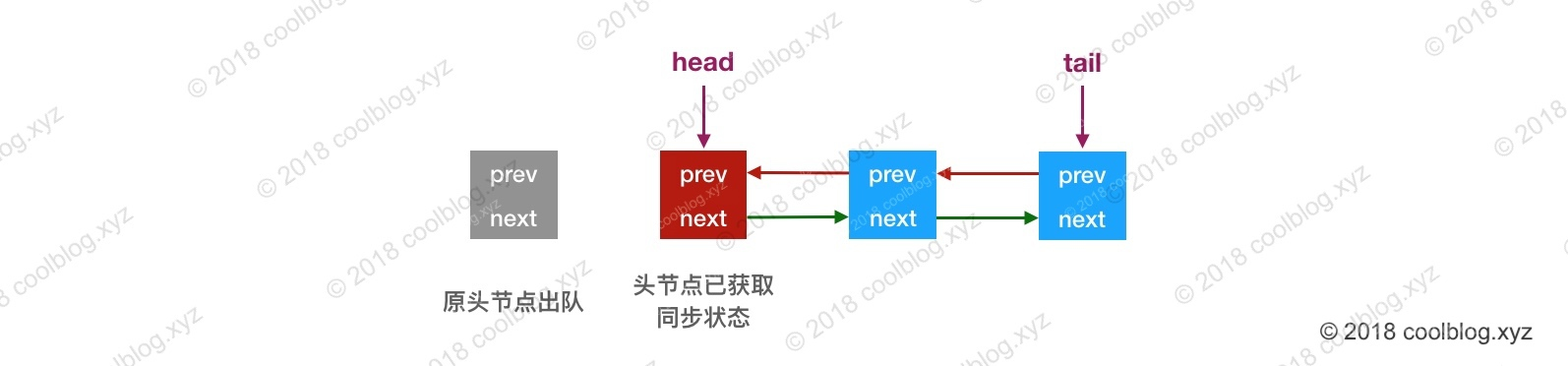
常用方法
主要介绍三组重要的方法,通过使用这三组方法即可实现一个同步组件。
第一组方法是用于访问/设置同步状态的,如下:
| 方法 | 说明 |
|---|---|
| int getState() | 设置同步状态 |
| void setState() | 设置同步状态 |
| boolean compareAndSetState(int expect, int update) | 通过 CAS 设置同步状态 |
第二组方需要由同步组件覆写。如下:
| 方法 | 说明 |
|---|---|
| boolean tryAcquire(int arg) | 独占式获取同步状态 |
| boolean tryRelease(int arg) | 独占式释放同步状态 |
| int tryAcquireShared(int arg) | 共享式获取同步状态 |
| boolean tryReleaseShared(int arg) | 共享式私房同步状态 |
| boolean isHeldExclusively() | 检测当前线程是否获取独占锁 |
第三组方法是一组模板方法,同步组件可直接调用。如下:
| 方法 | 说明 |
|---|---|
| void acquire(int arg) | 独占式获取同步状态,该方法将会调用 tryAcquire 尝试获取同步状态。获取成功则返回,获取失败,线程进入同步队列等待。 |
| void acquireInterruptibly(int arg) | 响应中断版的 acquire |
| boolean tryAcquireNanos(int arg,long nanos) | 超时+响应中断版的 acquire |
| void acquireShared(int arg) | 共享式获取同步状态,同一时刻可能会有多个线程获得同步状态。比如读写锁的读锁就是就是调用这个方法获取同步状态的。 |
| void acquireSharedInterruptibly(int arg) | 响应中断版的 acquireShared |
| boolean tryAcquireSharedNanos(int arg,long nanos) | 超时+响应中断版的 acquireShared |
| boolean release(int arg) | 独占式释放同步状态 |
| boolean releaseShared(int arg) | 共享式释放同步状态 |
上面列举了一堆方法,看似繁杂。但稍微理一下,就会发现上面诸多方法无非就两大类:一类是独占式获取和释放独占状态,另一类是共享式获取和释放同步状态。
源码
¶线程队列节点结构
在并发的情况下,AQS 会将未获取同步状态的线程将会封装成节点,并将其放入同步队列尾部。同步队列中的节点除了要保存线程,还要保存等待状态。不管是独占式还是共享式,在获取状态失败时都会用到节点类。所以这里我们要先看一下节点类的实现,为后面的源码分析进行简单铺垫。源码如下:
1 | static final class Node { |
¶独占模式
¶获取同步状态
独占式获取同步状态时通过 acquire 进行的,下面来分析一下该方法的源码。如下:
1 | /** |
到这里,独占式获取同步状态的分析就讲完了。如果仅分析获取同步状态的大致流程,那么这个流程并不难。但若深入到细节之中,还是需要思考思考。这里对独占式获取同步状态的大致流程做个总结,如下:
- 调用 tryAcquire 方法尝试获取同步状态
- 获取成功,直接返回
- 获取失败,将线程封装到节点中,并将节点入队
- 入队节点在 acquireQueued 方法中自旋获取同步状态
- 若节点的前驱节点是头节点,则再次调用 tryAcquire 尝试获取同步状态
- 获取成功,当前节点将自己设为头节点并返回
- 获取失败,可能再次尝试,也可能会被阻塞。这里简单认为会被阻塞。
上面的步骤对应下面的流程图: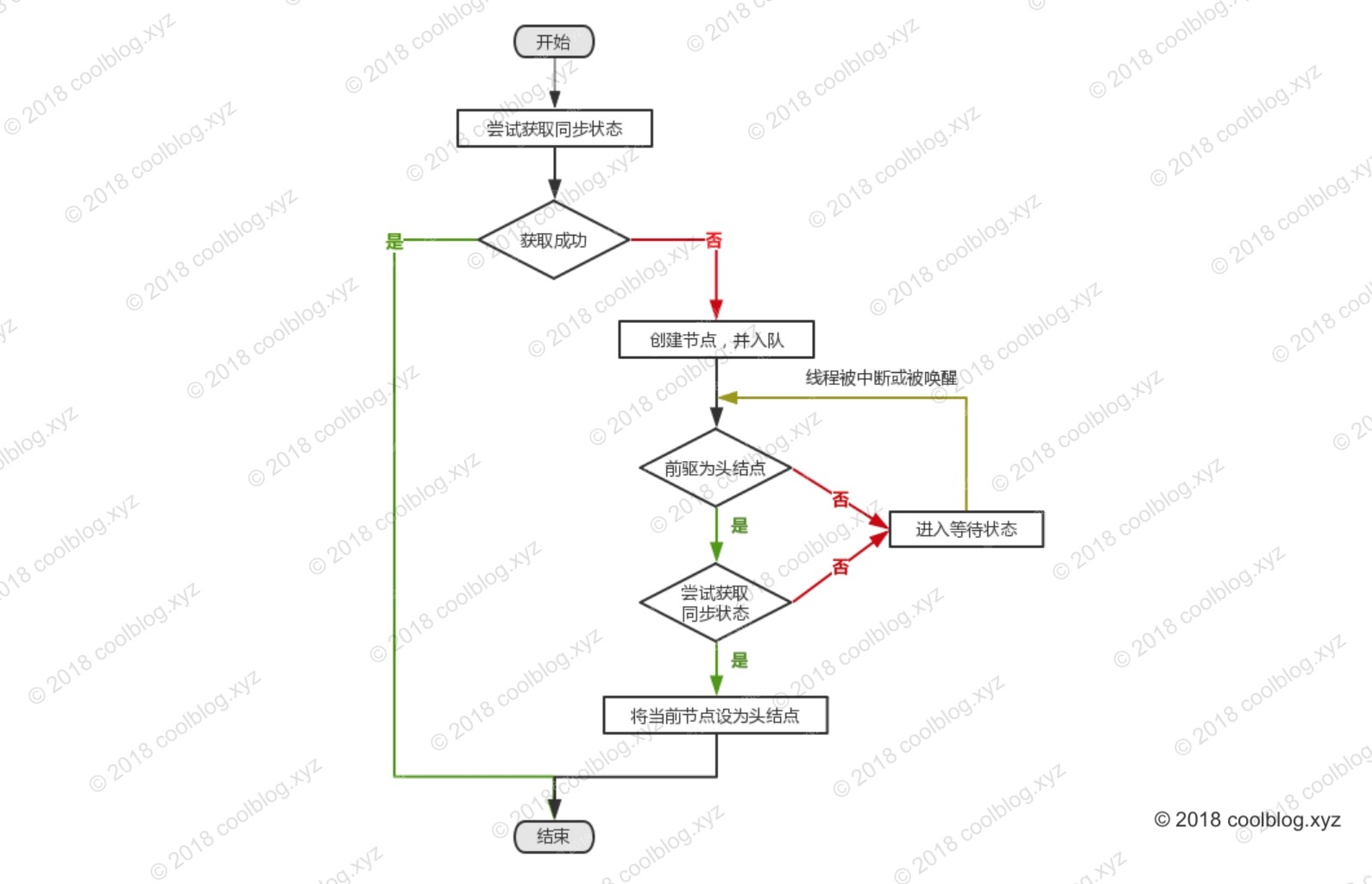
¶释放同步状态
相对于获取同步状态,释放同步状态的过程则要简单的多,这里简单罗列一下步骤:
- 调用 tryRelease(arg) 尝试释放同步状态
- 根据条件判断是否应该唤醒后继线程
就两个步骤,下面看一下源码分析。
1 | public final boolean release(int arg) { |
¶共享模式
与独占模式不同,共享模式下,同一时刻会有多个线程获取共享同步状态。共享模式是实现读写锁中的读锁、CountDownLatch 和 Semaphore 等同步组件的基础,搞懂了,再去理解一些共享同步组件就不难了。
¶获取同步状态
共享类型的节点获取共享同步状态后,如果后继节点也是共享类型节点,当前节点则会唤醒后继节点。这样,多个节点线程即可同时获取共享同步状态。
1 | public final void acquireShared(int arg) { |
到这里,共享模式下获取同步状态的逻辑就分析完了,不过我这里只做了简单分析。相对于独占式获取同步状态,共享式的情况更为复杂。独占模式下,只有一个节点线程可以成功获取同步状态,也只有获取已同步状态节点线程才可以释放同步状态。但在共享模式下,多个共享节点线程可以同时获得同步状态,在一些线程获取同步状态的同时,可能还会有另外一些线程正在释放同步状态。所以,共享模式更为复杂。这里我的脑力跟不上了,没法面面俱到的分析。
最后说一下共享模式下获取同步状态的大致流程,如下:
- 获取共享同步状态
- 若获取失败,则生成节点,并入队
- 如果前驱为头结点,再次尝试获取共享同步状态
- 获取成功则将自己设为头结点,如果后继节点是共享类型的,则唤醒
- 若失败,将节点状态设为 SIGNAL,再次尝试。若再次失败,线程进入等待状态
¶释放同步状态
释放共享状态主要逻辑在 doReleaseShared 中,doReleaseShared 上节已经分析过,这里就不赘述了。共享节点线程在获取同步状态和释放同步状态时都会调用 doReleaseShared,所以 doReleaseShared 是多线程竞争集中的地方。
1 | public final boolean releaseShared(int arg) { |
PROPAGATE 状态存在的意义
AQS 的节点有几种不同的状态,PROPAGATE 字面意义,即向后传播唤醒动作。
那么就有两个问题:
- PROPAGATE 状态用在哪里,以及怎样向后传播唤醒动作的?
- 引入 PROPAGATE 状态是为了解决什么问题?
¶利用 PROPAGATE 传播唤醒动作
PROPAGATE 状态是用来传播唤醒动作的,那么它是在哪里进行传播的呢?答案是在setHeadAndPropagate方法中,这里再来看看 setHeadAndPropagate 方法的实现:
1 | private void setHeadAndPropagate(Node node, int propagate) { |
注意看 setHeadAndPropagate 方法中那个长长的判断语句,其中有一个条件是h.waitStatus < 0,当 h.waitStatus = SIGNAL(-1) 或 PROPAGATE(-3) 是,这个条件就会成立。那么 PROPAGATE 状态是在何时被设置的呢?答案是在doReleaseShared方法中,如下:
1 | private void doReleaseShared() { |
再回到 setHeadAndPropagate 的实现,该方法既然引入了h.waitStatus < 0这个条件,就意味着仅靠条件propagate > 0判断是否唤醒后继节点线程的机制是不充分的。为啥?
¶引入 PROPAGATE 所解决的问题
PROPAGATE 的引入是为了解决一个 BUG – JDK-6801020,复现这个 BUG 的代码如下:
1 | import java.util.concurrent.Semaphore; |
根据 BUG 的描述消息可知 JDK 6u11,6u17 两个版本受到影响。那么,接下来再来看看引起这个 BUG 的代码 – JDK 6u17 中 setHeadAndPropagate 和 releaseShared 两个方法源码,如下:
1 | private void setHeadAndPropagate(Node node, int propagate) { |
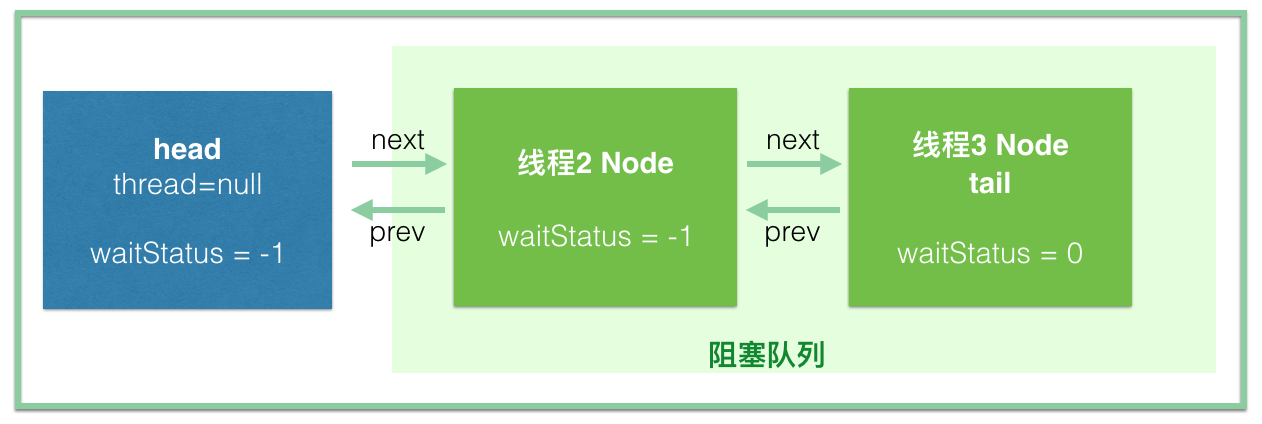
下面来简单说明 TestSemaphore 这个类的逻辑。这个类持有一个数值为 0 的信号量对象,并创建了4个线程,线程 t1 和 t2 用于获取信号量,t3 和 t4 则是调用 release() 方法释放信号量。在一般情况下,TestSemaphore 这个类的代码都可以正常执行。但当有极端情况出现时,可能会导致同步队列挂掉。这里演绎一下这个极端情况,考虑某次循环时,队列结构如下: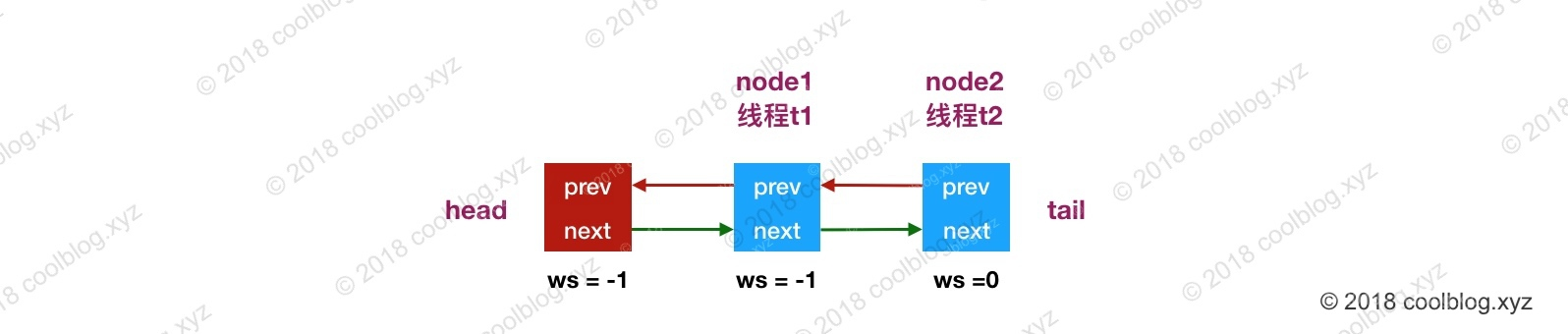
- 时刻1:线程 t3 调用 unparkSuccessor 方法,head 节点状态由 SIGNAL(-1) 变为0,并唤醒线程 t1。此时信号量数值为1。
- 时刻2:线程 t1 恢复运行,t1 调用 Semaphore.NonfairSync 的 tryAcquireShared,返回0。然后线程 t1 被切换,暂停运行。
- 时刻3:线程 t4 调用 releaseShared 方法,因 head 的状态为0,所以 t4 不会调用 unparkSuccessor 方法。
- 时刻4:线程 t1 恢复运行,t1 成功获取信号量,调用 setHeadAndPropagate。但因为 propagate = 0,线程 t1 无法调用 unparkSuccessor 唤醒线程 t2,t2 面临无线程唤醒的情况。因为 t2 无法退出等待状态,所以 t2.join 会阻塞主线程,导致程序挂住。
下面再来看一下修复 BUG 后的代码,根据 BUG 详情页显示,该 BUG 在 JDK 1.7 中被修复。这里找一个 JDK 7 较早版本(JDK 7u10)的代码看一下,如下:
1 | private void setHeadAndPropagate(Node node, int propagate) { |
在按照上面的代码演绎一下逻辑,如下:
- 时刻1:线程 t3 调用 unparkSuccessor 方法,head 节点状态由 SIGNAL(-1) 变为0,并唤醒线程t1。此时信号量数值为1。
- 时刻2:线程 t1 恢复运行,t1 调用 Semaphore.NonfairSync 的 tryAcquireShared,返回0。然后线程 t1 被切换,暂停运行。
- 时刻3:线程 t4 调用 releaseShared 方法,检测到h.waitStatus = 0,t4 将头节点等待状态由0设为PROPAGATE(-3)。
- 时刻4:线程 t1 恢复运行,t1 成功获取信号量,调用 setHeadAndPropagate。因 propagate = 0,propagate > 0 条件不满足。而 h.waitStatus = PROPAGATE(-3),所以条件h.waitStatus < 0成立。进而,线程 t1 可以唤醒线程 t2,完成唤醒动作的传播。
¶PROPAGATE 状态用在哪里,以及怎样向后传播唤醒动作的?
PROPAGATE 状态用在 setHeadAndPropagate。当头节点状态被设为 PROPAGATE 后,后继节点成为新的头结点后。若 propagate > 0 条件不成立,则根据条件h.waitStatus < 0成立与否,来决定是否唤醒后继节点,即向后传播唤醒动作。
¶引入 PROPAGATE 状态是为了解决什么问题?
引入 PROPAGATE 状态是为了解决并发释放信号量所导致部分请求信号量的线程无法被唤醒的问题。